Facebook Reality Labs’ prototype photorealistic avatars can now work without face tracking cameras, bringing the technology’s potential deployment closer than ever.
Facebook, which owns the Oculus brand of VR products (which, as of yesterday, fall under the Facebook Reality Labs label), first showed off work on ‘Codec Avatars’ back in March 2019. Powered by machine learning, the avatars are generated using a specialized capture rig with 132 cameras. Once generated, they can be driven by a prototype VR headset with three cameras; facing the left eye, right eye, and mouth.
Even if codec avatars can in future be generated with widely accessible hardware, no consumer VR headset today has the necessary cameras facing the mouth and upper face. Adding these cameras to headsets would increase cost- and be dead weight in offline experiences.
That’s why this latest incarnation of Codec Avatars does away with the need for dedicated face cameras. The new neural network fuses a headset’s eye-tracking data with the microphone audio feed to infer the likely facial expression.
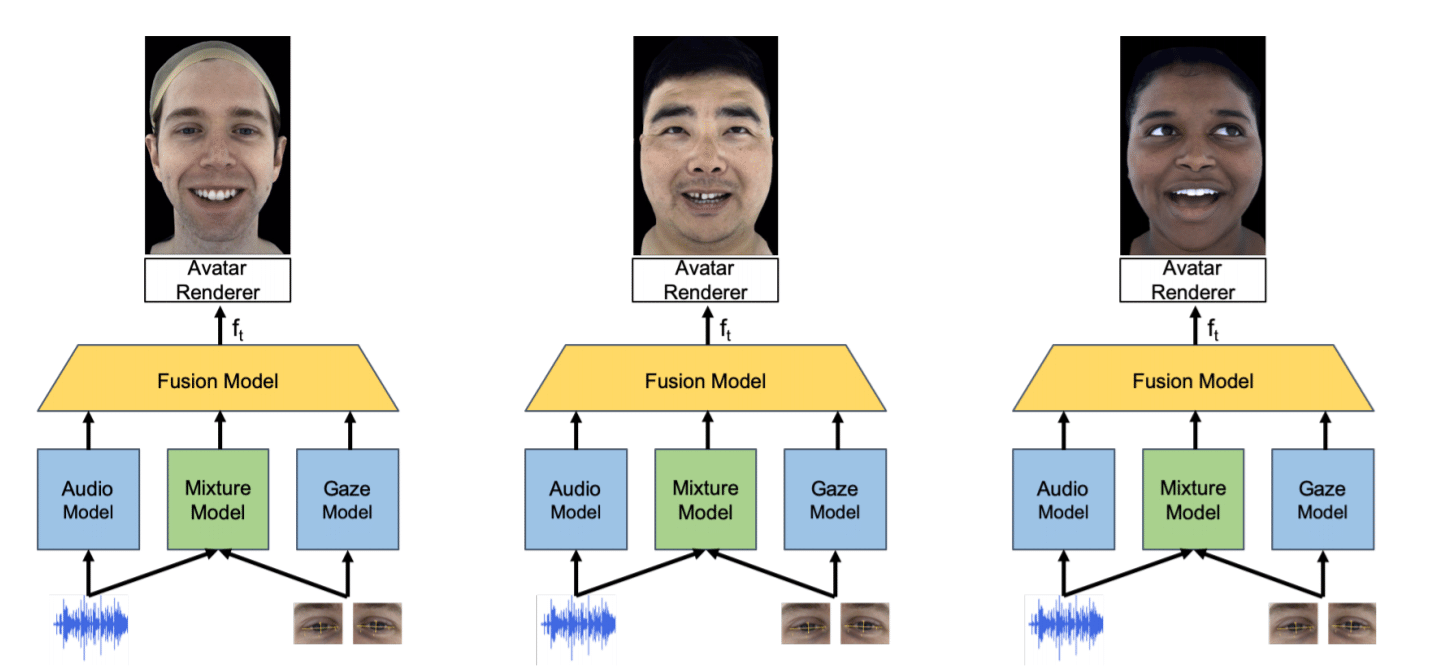
Unlike facial expression cameras, eye tracking could be useful for much more than avatars. It could enable prioritizing resolution based on gaze (known as foveated rendering) as well as precise optical calibration, and even variable focus optics with realistic blur. An Oculus headset sporting eye-tracking seems like a question of when, not if.
So does this approach really work? Can a neural network really infer facial expression from only eye-tracking directions and microphone audio? Based on the video examples provided- it looks like the answer is yes.
The researchers say the network can even pick up the audio cues for subtle actions like wetting your lips with your tongue. It’s noted that picking up such cues would require the headset to have a high-quality microphone, though.
There is of course a major catch. Training the model requires a multi-camera 3D capture setup with 45 minutes of unique data for each test user. When first shown in 2018, Codec Avatars were described by Facebook as “years away”. While this new research makes the hardware needed to drive avatars more practical, it still doesn’t solve the core issues of generating the avatar in the first place.
If such problems can be solved, the technology could have tremendous implications. For most, telepresence today is limited to grids of webcams on a 2D monitor. The ability to see photorealistic representations of others in true scale, fully tracked from real motion, with the ability to make eye contact, could fundamentally change the need for face to face interaction.